Involuntary singing
This is a fun trick I’ve employed several times: manipulating spoken word so that it sounds like singing (kind of).
The general process involves time-stretching and pitch-shifting a source material so that it matches a song’s tempo and key. This is a very broad overview of how it works, I won’t get into too much detail.
Here’s how it sounds, step-by-step:
I always start by plotting out a melody with some basic synth sound, using The Power of My Imagination™ to envision the original audio “singing” whatever tune I come up with. This is what I call a “guide,” and I’ll render it by itself so I can use it as a reference while editing the source.
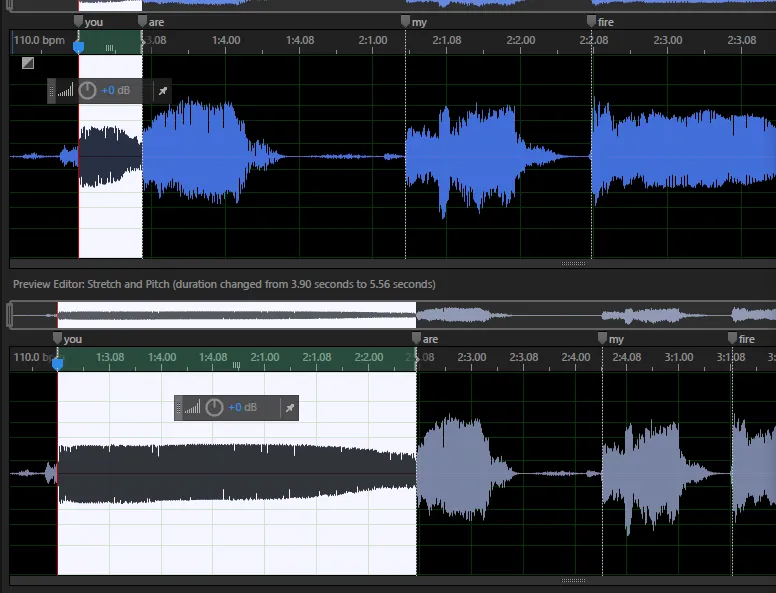
Once I have a crude idea of what I want the end result to sound like, the next step is time-stretching (or “beat matching”) the source file so that it lines up with the tempo of the song I’m writing. In this particular example I used Adobe Audition, but any wave editor with time manipulation tools should work. These processors usually come with a varying set of parameters that will directly affect accuracy, however I tend to just make sure that I have pitch preservation enabled and leave everything else on default or auto. It may sound a bit grainy, and the artifacts are very audible in the samples embedded in this post, but I actually like it that way!
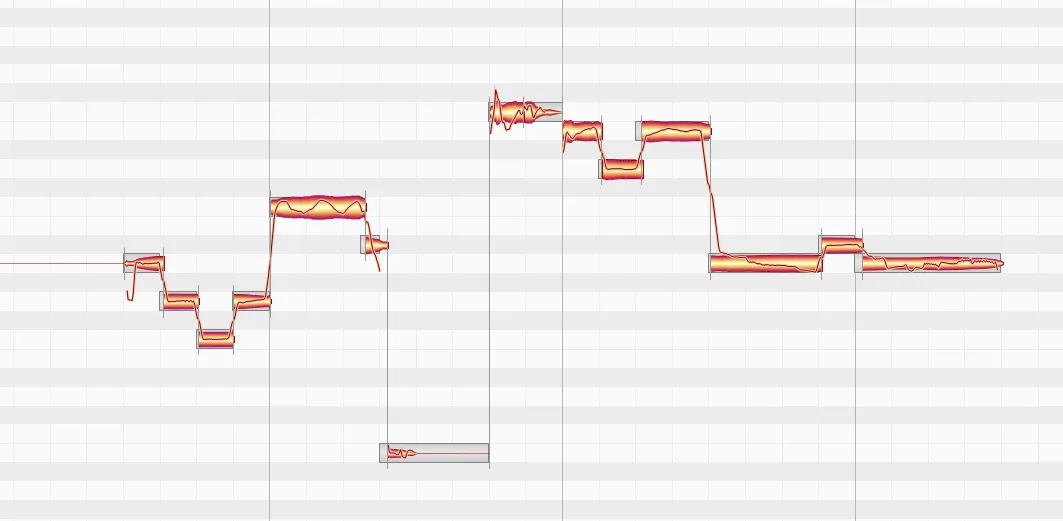
After all of the words/syllables are resized, I should be able to play it back in my song arrangement and hear it match the beat. The next step is adjusting the pitch to match it along with the melody. My tool of choice here is Celemony’s Melodyne – it’s an amazing application that offers a lot of additional control over note properties, such as attack time or pitch drift. I don’t do too much complicated stuff here outside of manual note adjustment, but I do like to cut the segments apart and snap everything to the nearest whole note before doing anything else.
Almost done! All that’s left to do is clean up any unwanted noise/clicks/pops and then toss the new files into the song. I used an EQ to hone in on the voice, and added some reverb to it. I also created a few extra harmony layers in Melodyne that I think sound pretty nice.
The source material comes from Noxious – you can find the original clip here.